
El modelado matemático de las epidemias es una técnica que usa un lenguaje y herramientas matemáticas para explicar y predecir la evolución de las mismas. Aquí, como en muchos otros campos, generar un modelo matemático puede servir para comprender los aspectos esenciales de la interacción con el agente infeccioso, determinar qué datos son indicativos, disponer de un marco teórico donde se pueden realizar experimentos virtuales, etc.
En una epidemia, la enfermedad puede infectar a los individuos de manera aleatoria. Sin embargo, la ley de los grandes números indica que la cantidad de individuos infectados se hace cada vez más predecible, a medida que aumenta el tamaño de la población. Por este motivo, para grandes poblaciones, resulta apropiado modelar la evolución a través de ecuaciones diferenciales. Contrariamente, para poblaciones pequeñas las fluctuaciones pueden ser considerables, la probabilidad se hace presente y se debe recurrir al modelado estocástico, con variables aleatorias.
Modelos simples
En el modelo SIR (ver mi entrada Epidemias), debido a W.O. Kermack y A.G. McKendrick, hay tres tipos de individuos: susceptibles, infectados y recuperados; sus evoluciones en el tiempo están respectivamente descritas por las funciones \(S = S(t)\), \(I = I(t)\) y \(R = R(t)\), que deben verificar el sistema diferencial
Aquí, \(r\) y \(a\) son constantes positivas; \(r\) es la tasa de infección (indica la proporcionalidad con la que un contacto de un susceptible y un infectado influye en el cambio en el número de infectados); por otra parte, \(a\) es la tasa de recuperación (indica la proporcionalidad con la que los infectados influyen en el cambio que experimenta el número de recuperados). Se acepta en este modelo que los recuperados no van a enfermar nuevamente ni tampoco van a transmitir la enfermedad a otros. También se acepta que la población total es fija, es decir \(S(t) + I(t) + R(t) \equiv N\) (constante). Por supuesto, esta hipótesis simplifica notablemente la situación.
He aquí dos variantes del modelo SIR:
- El modelo SIRp, basado en las ecuaciones \(\dot S = -r SI + \mu(N-S)\), \(\dot I = r SI – a I – \mu I\), \(\dot R = a I – \mu R\) (\(\mu\) es una nueva constante positiva), donde se supone que algunos individuos susceptibles nacen y algunos individuos infectados o recuperados mueren a lo largo del tiempo.
- El modelo SIRS, en donde, además, los individuos recuperados pueden perder la inmunidad y volver a ser susceptibles: \(\dot S = -r SI + \mu(N-S) + \nu R\), \(\dot I = r SI – a I – \mu I\), \(\dot R = a I – (\mu + \nu) R\). La constante positiva \(\nu\) indica la proporción de individuos recuperados que dejan de serlo.
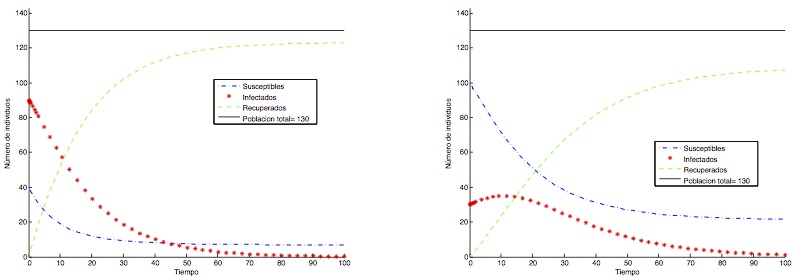
Fijemos ideas: concentrémonos en el modelo SIR. Para cada terna de datos iniciales \((S_0,I_0,R_0)\) con \(S_0 + I_0 + R_0 = N\), existe una única solución con \(S(t) + I(t) + R(t) \equiv N\). Las cuestiones más importantes son (a) saber si para unas constantes \(r\) y \(a\) dadas la infección se propaga o no y, en tal caso, (b) determinar cuál es su evolución temporal y cuándo comienza a decaer.
Es usual considerar las cantidades \(\rho := a/r\) (tasa de recuperación relativa) y \(r_0 := S_0/\rho\) (tasa reproductiva básica). No es difícil probar que las respuestas a estas cuestiones vienen dadas por el valor de \(r_0\): si \(r_0 \leq 1\), \(t \to I(t)\) es decreciente para \(t > 0\) y la infección no tiene posibilidades de propagarse; por el contrario, si \(r_0 > 1\), \(t \to I(t)\) es inicialmente creciente, la infección se propaga durante un tiempo y luego tiende a desaparecer por falta de individuos infectados.
Modelos no tan simples y ondas endémicas
En los modelos precedentes, hemos hecho una serie de suposiciones simplificadoras. Entre otras, que la población no está extendida espacialmente y se encuentra bien «mezclada».
Podríamos haber tenido en cuenta también el efecto de la edad, la presencia de sistemas de vacunación y tratamiento, la estructura social de la población, etc. Naturalmente, todo esto conduce a modelos de mayor complicación, donde determinar el comportamiento de las soluciones puede ser mucho más difícil.
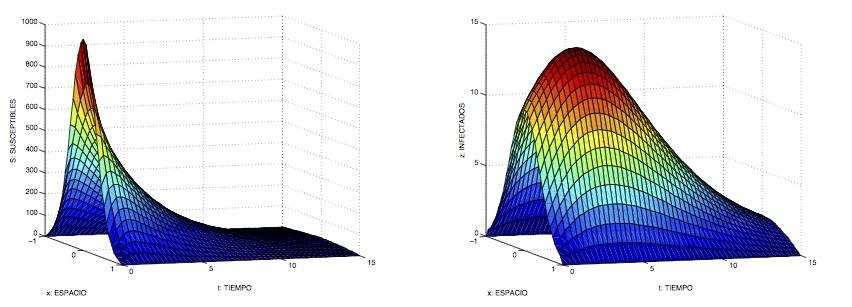
En particular, consideremos el modelo siguiente, donde aceptamos que los individuos susceptibles e infectados están distribuidos a lo largo y ancho de un hábitat 1D (un intervalo), respectivamente con densidades de población \(S = S(x,t)\) e \(I = I(x,t)\):
$$S_t – D S_{xx} = -r SI, \ \ I_t – D I_{xx} = r SI – a I.$$
Aquí, \(D\) es una constante positiva que indica la rapidez e intensidad con la que los individuos tienden a repartirse y \(S_t\), \(S_{xx}\), \(I_t\), \(I_{xx}\) denotan derivadas parciales. Las ecuaciones precedentes deben ser complementadas con condiciones iniciales (en \(t = 0\)) y condiciones de contorno (en \(x = a\) y \(x = b\), siendo \(a\) y \(b\) los extremos del intervalo).
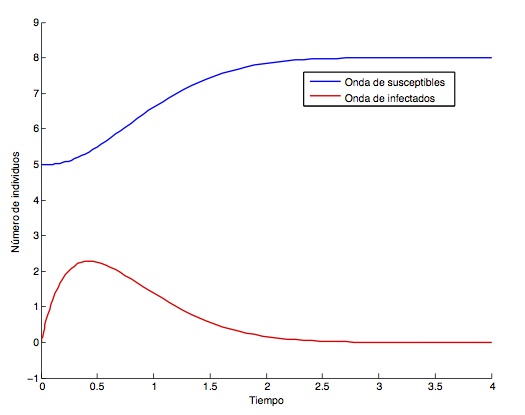
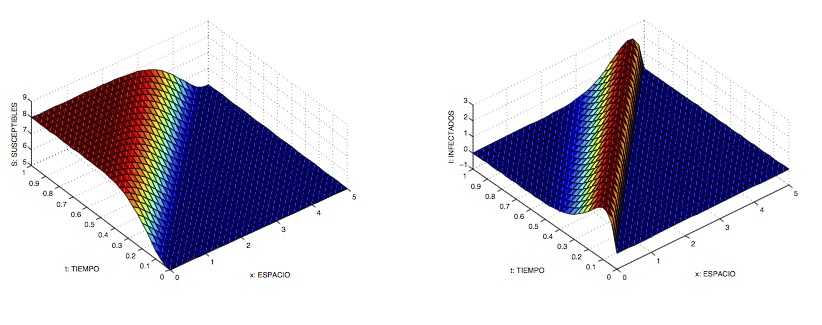
Supongamos que \(a = -\infty\), \(b = +\infty\) e inicialmente \(S(x,0) = S_0\) (constante). Un análisis adecuado muestra de nuevo que la cantidad \(r_0 = S_0/\rho\) determina la evolución del sistema. Así, si \(r_0 > 1\), existen soluciones cuyo comportamiento es de la forma $latex S(x,t) \approx \hat S(x-ct)$, \(I(x,t) \approx \hat I(x-ct)\) para determinados valores de \(c\). Estas soluciones «se propagan como ondas planas» con velocidad \(c\) y se denominan ondas epidémicas. Se puede interpretar entonces que, para estos valores de \(r_0\), las infecciones «avanzan» con velocidad \(c\). Por el contrario, si \(r_0 < 1\), no existen soluciones con esta estructura. Podemos establecer una conexión de este comportamiento ondulatorio con los distintos brotes de peste que tuvieron lugar en Europa en años pasados: las plagas de Islandia (1402-1404), Londres (1592–1594), Milán (1629-1631), Sevilla (1649-1650), Londres (1665-1666), Viena (1679-1682), Marsella (1720-1722), etc.
En el marco de los sistemas precedentes, tiene gran interés considerar problemas inversos, también conocidos como problemas de identificación de parámetros. Por ejemplo, tiene sentido intentar calcular la constante \(r\) del modelo SIR a partir de \(a\), los datos iniciales para \(S\), \(I\) y \(R\) y una información adicional sobre estas variables (una posibilidad es el valor de \(R(T)\), donde \(T\) es dado; de hecho, no es fácil calcular \(r\) directamente, a partir de datos experimentales). Naturalmente, en el caso del sistema de ecuaciones en derivadas parciales presentado más arriba, esto requiere mucho más esfuerzo.
Dejar una contestacion